Parallel Computing on Ceres with Python and Dask¶
adapted from https://github.com/willirath/dask_jobqueue_workshop_materials by Kerrie Geil, USDA-ARS August 2020
The Goal¶
Interactive data analysis on very large datasets. The tools in this tutorial are most appropriate for analysis of large earth-science-type datasets.
For large dataset analysis, you'll want to run parallel (instead of serial) computations to save time. On a high-performance computer (HPC), you could divide your computing into independent segments (batching) and submit multiple batch scripts to run compute jobs simultaneously or you could parallelize your codes using MPI (Message Passing Interface), a traditional method for parallel computing if your code is in C or Fortran. Actually, there is also an "MPI for Python" package, but the methods in this tutorial are much much simpler. Both the batching and MPI methods of parallelization do not allow for interactive analysis, such as analysis using a Jupyter notebook, which is often desired by the earth science research community. Note that interactive analysis here does not mean constant visual presentation of the data with a graphical user interface (GUI) such as in ArcGIS.
For earth-science-type data and analysis with Python, one of the simplest ways to run parallel computations in an interactive environment is with the Dask package.
Core Lessons¶
Using Dask to:
- set up SLURM clusters
- scale clusters
- use adaptive clusters
- view Dask diagnostics
This tutorial will demonstrate how to use Dask to manage compute jobs on a SLURM cluster (including setting up your SLURM compute cluster, scaling the cluster, and how to use an adaptive cluster to save compute resources for others). The tutorial will also explain how to access the Dask diagnostics dashboard to view the cluster working in real time.
Begin Tutorial: Parallel Computing on Ceres with Python and Dask¶
In this tutorial we will compute in parallel using Python's Dask package to communicate with the Ceres HPC SLURM job scheduler.
SLURM (Simple Linux Utility for Resource Management) is a workload manager for HPC systems. From the SLURM documentation, SLURM is "an open source... cluster management and job scheduling system for large and small Linux clusters. As a cluster workload manager, SLURM has three key functions. First, it allocates exclusive and/or non-exclusive access to resources (compute nodes) to users for some duration of time so they can perform work. Second, it provides a framework for starting, executing, and monitoring work (normally a parallel job) on the set of allocated nodes. Finally, it arbitrates contention for resources by managing a queue of pending work."
First Set up Your File Space¶
Create a folder in your home directory for the Dask worker error files
import os
homedir = os.environ['HOME']
daskpath=os.path.join(homedir, "dask-worker-space-can-be-deleted")
try:
os.mkdir(daskpath)
except OSError as error:
print(error)
Set up a SLURM Cluster with Dask¶
The first step is to create a SLURM cluster using the dask.distributed and dask_jobqueue packages. The SLURMCluster function can be interpreted as the settings/parameters for 1 SLURM compute job. Later, we can increase our compute power by "scaling our cluster", which means Dask will ask the SLURM scheduler to execute more than one job at a time for any given computation.
Here's a key to the dask_jobqueue.SLURMCluster input parameters in the code block below:
cores = Number of logical cores per job. This will be divided among the processes/workers. Can't be more than the lowest number of logical cores per node in the queue you choose, see https://scinet.usda.gov/guide/ceres/#partitions-or-queues.
processes = Number of processes per job (also known as Dask "workers" or "worker processes"). The number of cores per worker will be cores/processes. Can use 1 but more than 1 may help keep your computations running if cores/workers fail. For numeric computations (Numpy, Pandas, xarray, etc.), less workers may run significantly faster due to reduction in communication time. If your computations are mostly pure Python, it may be better to run with many workers each associated with only 1 core. Here is more info than you'll probably ever want to know about Dask workers.
memory = Memory per job. This will be divided among the processes/workers. See https://scinet.usda.gov/guide/ceres/#partitions-or-queues for the maximum memory per core you can request on each queue.
queue = Name of the Ceres queue, a.k.a. partition (e.g. short, medium, long, long60, mem, longmem, mem768, debug, brief-low, scavenger, etc.).
walltime = Time allowed before the job is timed out.
local_directory = local spill location if the core memory is exceeded, use /local/scratch a.k.a $TMPDIR
log_directory = Location to write the stdout and stderr files for each worker process. Simplest choice may be the directory you are running your code from.
python = The python executable. Add this parameter if you are running in a container to tell SLURM what container and conda env to use. Otherwise, it's not needed.
You can view additional parameters, methods, and attributes in the Dask documentation for dask_jobqueue.SLURMCluster.
from dask.distributed import Client
from dask_jobqueue import SLURMCluster
container='/lustre/project/geospatial_tutorials/wg_2020_ws/data_science_im_rs_vSCINetGeoWS_2020.sif'
env='py_geo'
cluster = SLURMCluster(
cores=40,
processes=1,
memory="120GB", #40 cores x 3GB/core
queue="short",
local_directory='$TMPDIR',
walltime="00:10:00",
log_directory=daskpath,
python="singularity -vv exec {} /opt/conda/envs/{}/bin/python".format(container,env)) #tell the cluster what container and conda env we're using
So far we have only set up a cluster, we have not started any compute jobs/workers running yet. We can verify this by issuing the following command in a Ceres terminal. Launch a terminal from the JupyterLab launcher and type:
squeue -u firstname.lastnameTo see the job script that will be used to start a job running on the Ceres HPC use the method .job_script() as shown in the code block below.
Here's a key to the output of the cluster.job_script() command below:
-J = Name of the job. This will appear in the "Name" column of the squeue output. "dask-worker" is the default value.
-e and -o = Name/Location of the stdout and stderr files for each job. This comes from the SLURMCLuster "log_directory" parameter.
-p = Name of the Ceres queue/partition. This comes from the SLURMCLuster "queue" parameter.
-n = Number of nodes.
--cpus-per-task = Number of cores per job (same as -N). This comes from the SLURMCluster "cores" parameter.
--mem = Memory per job. This comes from the SLURMCluster "memory" parameter.
-t = Time allowed before the job is timed out. This comes from the SLURMCluster parameter "walltime".
print(cluster.job_script())
Next, we must initialize a Dask Client, which opens a line of communication between Dask worker processes and the SLURM job scheduler by pointing to the address of the scheduler (tcp://10.1.8.84:41601).
client = Client(cluster)
client
Note: So far we have only set up a cluster and initialized a client. We still have not started any compute jobs running yet, as shown in the Cluster information above. We can also verify that no workers are running yet by issuing the squeue command in a Ceres terminal again as we did previously or we could access the Dask Diagnostics Dashboard for even more information.
Viewing the Dask Diagnostics Dashboard¶
We will now take a look at the Dask Dashboard to verify that there a no workers running in our cluster yet. Once we start computing, we will be able to use the Dashboard to see a visual representation of all the workers running.
At the very left edge of JupyterLab click the icon that looks like two orange leaves. If the Dask Dashboard extension is working you should see a bunch of orange colored boxes. Each one of these boxes allows you to visualize a different aspect of the compute job.
Click on the "workers" box to open a separate tab for visualizing the dask workers as they compute. Click over to that tab and right now you should see that there are no workers running yet. When you run a compute job you will see the workers populate the table on your dask workers tab.
Scale the Cluster to Start Computing¶
Now let's start multiple SLURM jobs computing.
from time import time, sleep #time for timing computation length, sleep for pausing while SLURM starts the requested jobs
cluster.scale(jobs=3) # scale to more jobs
sleep(15) # pause while SLURM starts up the jobs
client
The .scale() method actually starts the jobs running as shown in the Cluster information above.
A quick check of squeue will now show your multiple jobs running as well. Or click over to your Dask Workers tab and you'll see you have workers ready to compute.
When we set up our original cluster (equivalent of 1 SLURM job) we requested 40 cores spread over 2 workers. When we scaled our cluster to 3 jobs we now have 40x3=120 cores spread over 2x3=6 workers, as shown above. Note: you can also scale your cluster by cores, workers or memory as opposed to jobs.
Monte-Carlo Estimate of $\pi$¶
Now we will use the Monte-Carlo method of estimating $\pi$ to demonstrate how Dask can execute parallel computations with the SLURM Cluster we've built and scaled.
We estimate the number $\pi$ by exploiting that the area of a quarter circle of unit radius is $\pi/4$ and that hence the probability of any randomly chosen point in a unit square to lie in a unit circle centerd at a corner of the unit square is $\pi/4$ as well.
So for N randomly chosen pairs $(x, y)$ with $x\in[0, 1)$ and $y\in[0, 1)$, we count the number $N_{circ}$ of pairs that also satisfy $(x^2 + y^2) < 1$ and estimate $\pi \approx 4 \cdot N_{circ} / N$.
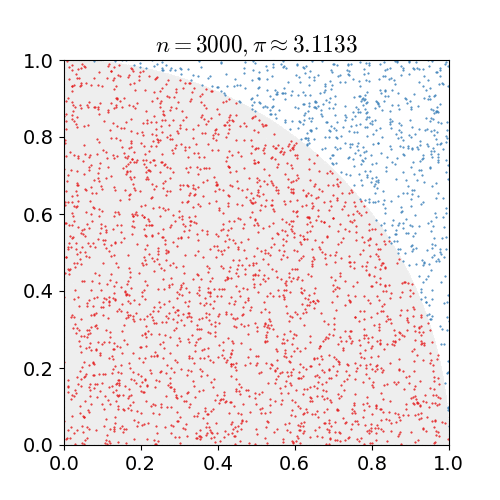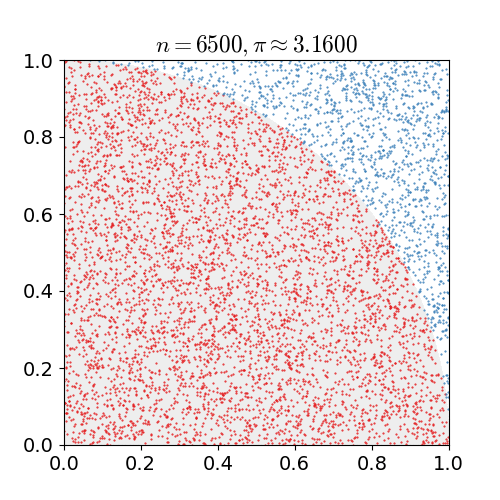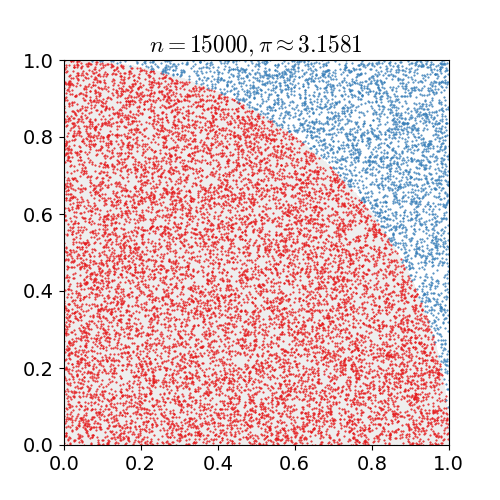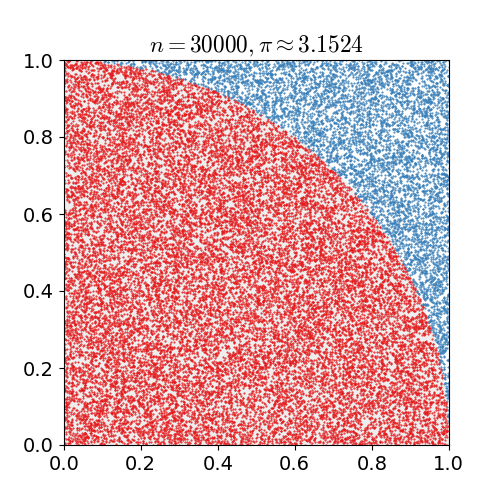
Let's define a function to compute $\pi$ and another function to print out some info during the compute.
import dask.array as da
import numpy as np
def calc_pi_mc(size_in_bytes, chunksize_in_bytes=200e6):
"""Calculate PI using a Monte Carlo estimate."""
size = int(size_in_bytes / 8) # size= no. of random numbers to generate (x & y vals), divide 8 bcz numpy float64's generated by random.uniform are 8 bytes
chunksize = int(chunksize_in_bytes / 8)
xy = da.random.uniform(0, 1, # this generates a set of x and y value pairs on the interval [0,1) of type float64
size=(size / 2, 2), # divide 2 because we are generating an equal number of x and y values (to get our points)
chunks=(chunksize / 2, 2))
in_circle = ((xy ** 2).sum(axis=-1) < 1) # a boolean array, True for points that fall inside the unit circle (x**2 + y**2 < 1)
pi = 4 * in_circle.mean() # mean= sum the number of True elements, divide by the total number of elements in the array
return pi
def print_pi_stats(size, pi, time_delta, num_workers):
"""Print pi, calculate offset from true value, and print some stats."""
print(f"{size / 1e9} GB\n"
f"\tMC pi: {pi : 13.11f}"
f"\tErr: {abs(pi - np.pi) : 10.3e}\n"
f"\tWorkers: {num_workers}"
f"\t\tTime: {time_delta : 7.3f}s")
The Actual Calculations¶
We loop over different volumes (1GB, 10GB, and 100GB) of double-precision random numbers (float64, 8 bytes each) and estimate $\pi$ as described above. Note, we call the function with the .compute() method to start the computations. To see the dask workers computing, execute the code block below and then quickly click over to your dask workers tab.
for size in (1e9 * n for n in (1, 10, 100)):
start = time()
pi = calc_pi_mc(size).compute()
elaps = time() - start
print_pi_stats(size, pi, time_delta=elaps,
num_workers=len(cluster.scheduler.workers))
Scale the Cluster to Twice its Size and Re-run the Same Calculations¶
We increase the number of workers times 2 and the re-run the experiments. You could also double the size of the cluster by doubling the number of jobs, cores, or memory.
new_num_workers = 2 * len(cluster.scheduler.workers)
print(f"Scaling from {len(cluster.scheduler.workers)} to {new_num_workers} workers.")
cluster.scale(new_num_workers)
# the following commands all get you the same amount of compute resources as above
#cluster.scale(12) # same as code above. default parameter is workers. (original num workers was 6)
#cluster.scale(jobs=6) # can scale by number of jobs
#cluster.scale(cores=240) # can also scale by cores
#cluster.scale(memory=600) # can also scale by memory
sleep(15)
client
for size in (1e9 * n for n in (1, 10, 100)):
start = time()
pi = calc_pi_mc(size).compute()
elaps = time() - start
print_pi_stats(size, pi,
time_delta=elaps,
num_workers=len(cluster.scheduler.workers))
Automatically Scale the Cluster Up and Down (Adaptive Cluster)¶
Using the .adapt() method will dynamically scale up the cluster when necessary but scale it down and save compute resources when not actively computing. Dask will ask the SLURM job scheduler to run more jobs, scaling up the cluster, when workload is high and shut the extra jobs down when workload is smaller.
Note that cluster scaling is bound by SCINet HPC user limitations. These limitations on the Ceres HPC are 400 cores, 1512GB memory, and 100 jobs max running simultaneously per user. So for example, if you set your cluster up with 40 cores per job and scale to 20 jobs (40x20=800cores) you will only get 400 cores (10 jobs) running at any time and the remaining requested jobs will not run. Your computations will still run successfully, but they will run on 10 jobs/400 cores instead of the requested 20 jobs/800 cores.
Watch how the cluster will scale down to the minimum a few seconds after being made adaptive.
ca = cluster.adapt(minimum_jobs=1, maximum_jobs=9);
sleep(5) # Allow for scale-down
client
Now, we'll repeat the calculations with our adaptive cluster and a larger workload. Watch the dash board!
for size in (n * 1e9 for n in (1, 10, 100, 1000)):
start = time()
pi = calc_pi_mc(size, min(size / 1000, 500e6)).compute()
elaps = time() - start
print_pi_stats(size, pi, time_delta=elaps,
num_workers=len(cluster.scheduler.workers))
sleep(5) # allow for scale-down time
client
What are the use cases for the adaptive cluster feature? Personally, I will be using the adaptive cluster when I have a code that contains a mix of lighter and heavier computations so I can use the minimum number of cores necessary for the lighter parts of the code and then have my cluster automagically scale up to handle heavier parts of the code without me having to think about it.
Complete listing of software used here¶
%conda list --explicit